
Llama 2 encompasses a range of generative text models both pretrained and fine-tuned with sizes from 7. We have collaborated with Kaggle to fully integrate Llama 2 offering pre-trained chat and CodeLlama in various sizes. In this section we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2. All three model sizes are available on HuggingFace for download Llama 2 models download 7B 13B. Were unlocking the power of these large language models Our latest version of Llama Llama 2 is now accessible. Meta released Llama 2 in the summer of 2023 The new version of Llama is fine-tuned with 40 more. In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models. The Llama2 7B model on huggingface meta-llamaLlama-2-7b has a pytorch pth file..

Llama 2
Open source free for research and commercial use. Result Llama 2 The next generation of our open source large language model available for free for. Result Today were introducing the availability of Llama 2 the next generation of. Result Yes we will publish benchmarks alongside the release If there are particular benchmarks partners. Result Llama 2 is a family of state-of-the-art open-access large language models released. Result Llama 2 brings this activity more fully out into the open with its allowance for..
Result Experience the power of Llama 2 the second-generation Large Language Model by Meta Choose from three model sizes pre-trained on 2 trillion tokens and. Result Welcome to llama-tokenizer-js playground Replace this text in the input field to see how token ization works. Result Llama2 Overview Usage tips Resources Llama Config Llama Tokenizer Llama Tokenizer Fast Llama Model Llama For CausalLM Llama For Sequence. Result In Llama 2 the size of the context in terms of number of tokens has doubled from 2048 to 4096 Your prompt should be easy to understand and provide enough. Result The LLaMA tokenizer is a BPE model based on sentencepiece One quirk of sentencepiece is that when decoding a sequence if the first token is the start of the..
Encord
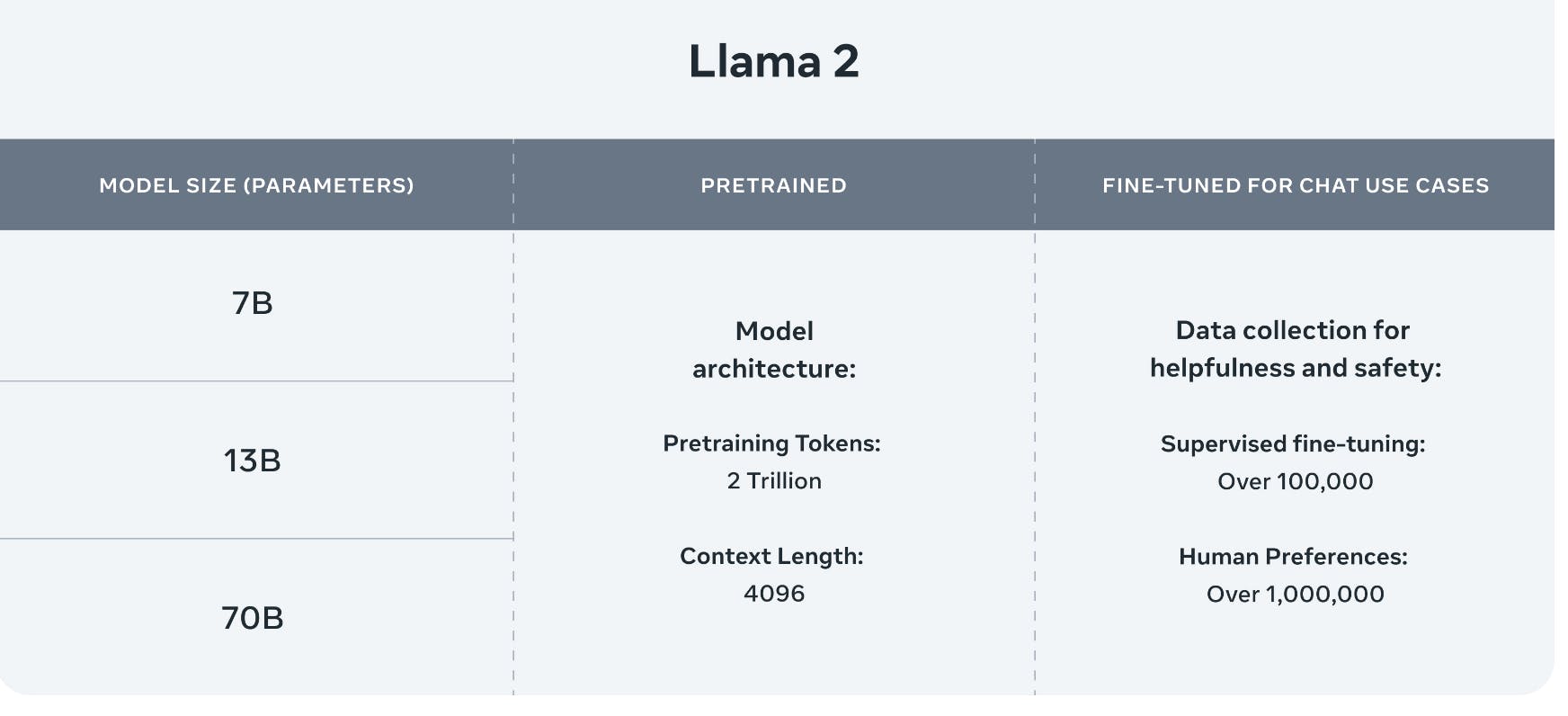
In this work we develop and release Llama 2 a collection of pretrained and fine-tuned large language models LLMs ranging in scale from 7 billion to 70 billion parameters. I Read the Entire 78-page Llama-2 Paper So You Dont Have To Published on 082323 Updated on 101123. The LLaMA-2 paper describes the architecture in good detail to help data scientists recreate fine-tune the models Unlike OpenAI papers where you have to deduce it. . Llama 2 is a family of pre-trained and fine-tuned large language models LLMs ranging in scale from 7B to 70B parameters from the AI group at Meta the parent company of..




Comments